Usando Regresión Logística para diferenciar cadenas
En este artículo vamos a entrenar a la máquina para comparar cadenas de texto usando regresión logística aplicando los algoritmos de Levenshtein (adaptado) y Jaro-Winkler.
Introducción
Los algoritmos tradicionales de Levenshtein y
Jaro-Winkler no siempre obtienen buenos resultados por sí mismos
debido a sus propias limitaciones. Por ejemplo, comparando nombres de calles.
Lejos de usar algoritmos más complejos, si combinamos la potencia de ambos podemos obtener un metodo más eficiente y aceptable para comparar las cadenas.
Basándonos en un conjunto de datos existente, vamos a entrenar la máquina usando regresión logística,
tomando como entradas el resultado de aplicar los algoritmos mencionados a cada cadena del conjunto de datos. Una vez entrenados, Tendremos un metodo eficiente para comparar automáticamente cadenas en el futuro.
Comenzamos
El conjunto de datos
Lo primero: el conjunto de datos. En mi caso, es una comparativa de calles de diferentes ciudades donde las dos primeras columnas son los nombres de las calles a comparar y la tercera representa,con un valor de 0 si existen diferencias significativas entre los nombres de las calles y, con un valor de 1 en caso contrario.
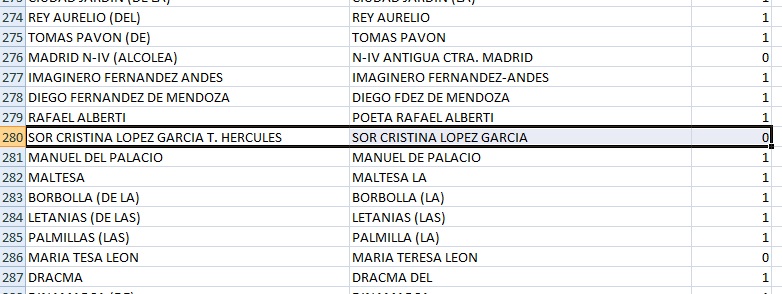
origen de datos
Exportaremos la hoja excel a un fichero .csv. El campo separador será '¦'. El fichero queda de esta forma:

origen de datos en CSV
Aplicando los algoritmos de Levenshtein y Jaro-Winkler
Usaremos la clase «Elements» para almacenar los datos y los resultados de aplicar los algoritmos.
public class Elements
{
public string OldName { get; set; }
public string NewName { get; set; }
// 1: las cadenas se consideran iguales - 0: las cadenas son diferentes
public int IsSame { get; set; }
public double Levenshtein { get; set; }
public double JaroWinkler { get; set; }
}
El código leerá todos los pares de cadenas y aplicará los algoritmos de distancia. El resultado se escribirá en un fichero donde las dos primeras columnas mostrarán los valores obtenidos como resultado de la aplicación de ambos algoritmos y la tercera columna mostrará 1 si las cadenas se pueden considerar las mismas o 0 en caso contrario (como la tercera columna del origen de datos).
string ruta = path + "\\" + filename + ".csv";
List lista = new List();
StreamReader sr = new StreamReader(ruta);
//Read the datasource and store in la List of Elements
while (!sr.EndOfStream)
{
string[] data = sr.ReadLine().Split('|');
lista.Add(new Elements()
{
NewName = ManejadorCadena.QuitaAcentos(data[0]).Trim().ToUpper(),
OldName = ManejadorCadena.QuitaAcentos(data[1]).Trim().ToUpper(),
IsSame = Convert.ToInt32(data[2])
});
}
sr.Close();
//Appliying the distance algorithms
lista.ForEach(item => DistanceAlgorithms.ApplyAlgorithms(item));
//Displaying the results
string salida = path + "\\train\\" + filename + ".out";
StreamWriter sw = new StreamWriter(salida, false);
lista.ForEach(item => sw.WriteLine(ManejadorCadena.BuildOutString(item, false).Replace(",", ".").Replace("|", ",")));
sw.Flush();
sw.Close();
Veamos el código de los algoritmos de distancia. (El código de Jaro-Winkler no es mio. Usé el siguiente tomado de stack overflow.)
using System;
namespace es.jutrera.logistic
{
public static class JaroWinklerDistance
{
/* The Winkler modification will not be applied unless the
* percent match was at or above the mWeightThreshold percent
* without the modification.
* Winkler's paper used a default value of 0.7
*/
private static readonly double mWeightThreshold = 0.7;
/* Size of the prefix to be concidered by the Winkler modification.
* Winkler's paper used a default value of 4
*/
private static readonly int mNumChars = 4;
///
/// Returns the Jaro-Winkler distance between the specified
/// strings. The distance is symmetric and will fall in the
/// range 0 (perfect match) to 1 (no match).
///
/// First String
/// Second String
///
/// Returns the Jaro-Winkler distance between the specified
/// strings. The distance is symmetric and will fall in the
/// range 0 (no match) to 1 (perfect match).
///
/// First String
/// Second String
///
Y ahora, el código del algoritmo de Levenshtein
using System;
namespace es.jutrera.logistic
{
public static class LevenshteinDistance
{
///
/// Applies the Levenshtein distance algorithm
///
/// First String
/// Second String
///
Una vez ejecutado, tenemos un fichero parecido a la imagen siguiente. Usaremos estos datos de salida para entrenar la máquina.
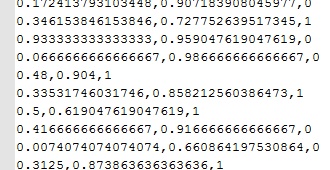
origen de datos para entrenamiento
Entrenando la máquina
Vamos a usar la aplicación Octave para realizar la regresión logística. Usaré lo aprendido en el cuso Machine Learning de Coursera (gracias Andrew NG).
El archivo train.m hará el trabajo.
using %% Initialization
clear ; close all; clc
%% Load Data
% The first two columns contains the X and the thirteen column contains the label.
data = load('source.out');
X = data(:, [1:2]); y = data(:, 3);
% Setup the data matrix
[m, n] = size(X);
X = [ones(m, 1) X];
% Initialize fitting parameters
initial_theta = zeros(n + 1, 1);
% Set options for fminunc
options = optimset('GradObj', 'on', 'MaxIter', 400);
% Run fminunc to obtain the optimal theta
% This function will return theta and the cost
[theta, cost] = fminunc(@(t)(costFunction(t, X, y)), initial_theta, options);
% Print theta to screen
fprintf('Cost at theta found by fminunc: %f\n', cost);
fprintf('theta: \n');
fprintf(' %f \n', theta);
% Plot Boundary
plotDecisionBoundary(theta, X, y);
% Put some labels
hold on;
% Labels and Legend
xlabel('Levenshtein')
ylabel('Jaro-Winkler')
% Specified in plot order
legend('Same', 'Not same')
pause;
hold off;
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
prob = sigmoid([1, 2, 0.8] * theta);
fprintf(['prediction probability (Lev: %f, J-W: %f): %f\n\n'], 2, 0.8, prob);
% Compute accuracy on our training set
p = predict(theta, X);
fprintf('Train Accuracy: %f\n', mean(double(p == y)) * 100);
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%train examples
error_data = load('cross.out');
X_cross = error_data(:, [1:2]);
y_cross = error_data(:, 3);
[error_train, error_val] = learningCurve(X, y, [ones(size(X_cross, 1), 1) X_cross], y_cross, theta);
figure;
hold on;
plot(1:m, error_train);
plot(1:m, error_val, 'color', 'g');
title('Regression Learning Curve');
xlabel('Number of training examples')
ylabel('Error')
%axis([0 13 0 100])
legend('Train', 'Cross Validation')
pause;
hold off;
fprintf('Program paused. Press enter to continue.\n');
pause;
El resultado de la ejecución del código se muestra en la siguiente imagen.
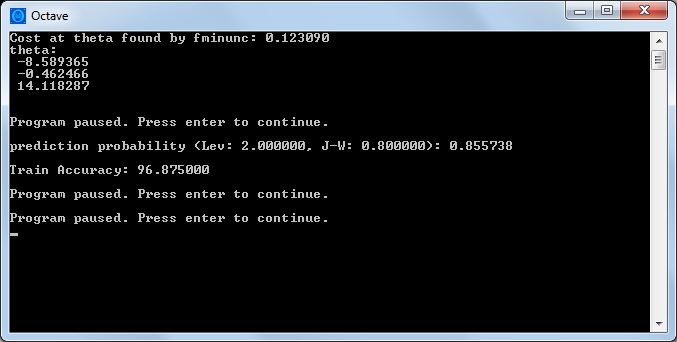
resultado del entrenamiento
La matriz theta muestra los valores de los coeficientes calculados para las entradas. Vamos a verlo en el siguiente gráfico. Los valores + representan cuando dos cadenas son la misma y Ø en caso contrario.
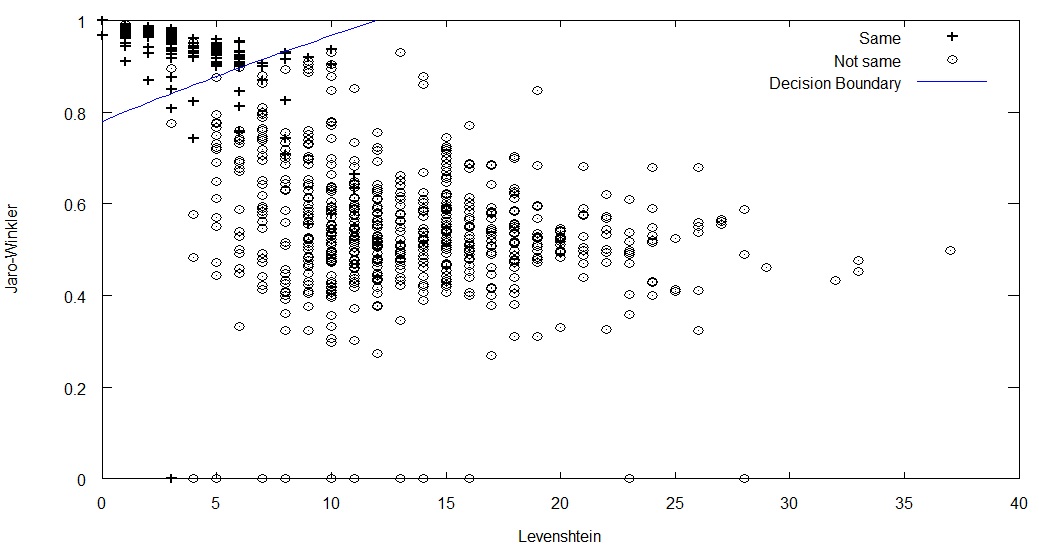
gráfico de resultados
La línea de decisión se ve correcta. Si hacemos una predicción con dos cadenas que tengan un valor de 2.0 usando Levenshtein y 0.8 con Jaro-Winkler, La probabilidad de ambas cadenas de ser finalmente las mismas (sin diferencias significativas) es aproximadamente de 0.85, tomando como grado de decisión de igualdad si la probabilidad es mayor o igual a 0.5 y no iguales cuando la probabilidad sea menor que 0.5, podremos decir las dos cadenas no son presentan diferencias significativas.
Veamos el gráfico de validación cruzada
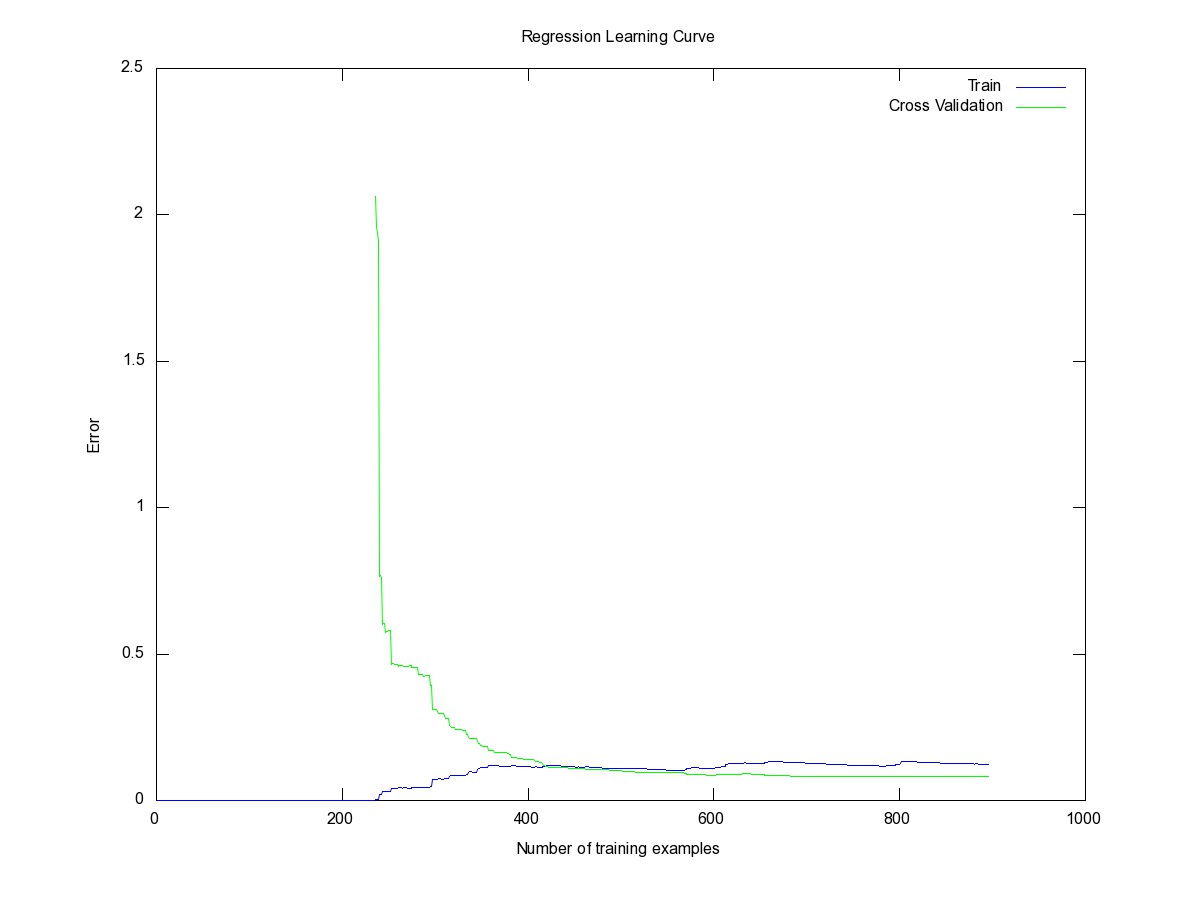
validación cruzada
Podemos que el valor para el error es bueno y la curvatura de la validación cruzada es aceptable.
Conclusión final
Terminado el estudio, hemos obtenido un algoritmo que nos permite identificar si existen cambios significativos entre dos cadenas de texto. Como se puede ver, nos provee de una herramienta un poco más eficaz que el hecho de ejecutar un algoritmo de distancia. Mientras que el algoritmo de Jaro-Winkler es un poco más eficiente, una vez combinado con el de Levenshtein y aplicado a un origen de datos de entrenamiento, podremos ver que el resultado se ajusta mejor a lo esperado.
Aplicando diferentes funciones
Para terminar, he aplicado otras funciones de hipótesis (lineal, cuadrática y cúbica) para probar cómo responden. Los resultados son buenos y pueden ajustarse correctamente (Algunos mejor que la usada en el artículo). En la siguiente figura muestro el gráfico de decisión de estas funciones. ¿Adivinas cual es cual?
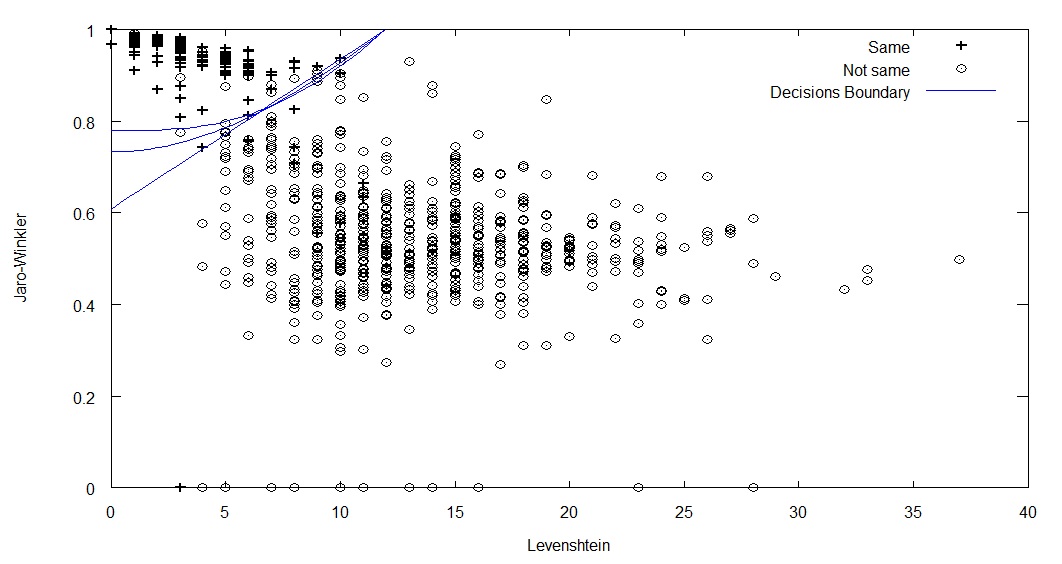
Gráfico de desición de las otras funciones de hipótesis